LLM'leri ve Halüsinasyonları Anlamak
Büyük Dil Modellerini (LLM'leri) ile giderek artan etkileşimimizde karşılaştığımız önemli bir sorun olan halüsinasyonları, nedenlerini ve nasıl azaltılabileceğini keşfedin.
LLM’ler
Bölümü dinlemek için 👇️👇️👇️👇
Yapay zeka modelleri hayatımızın her alanına girerken, özellikle Büyük Dil Modelleri (LLM’ler) ile etkileşimimiz giderek artıyor. Ancak bu devrimsel teknolojinin ardında, zaman zaman karşımıza çıkan ve kullanıcı deneyimini doğrudan etkileyen önemli bir sorun var: Halüsinasyonlar. Bu yazıda, LLM’lerin derinliklerine inip onları anlamaya çalışacak ve ardından bu “uydurma” davranışın nedenlerini ve nasıl azaltılabileceğini keşfedeceğiz
LLM’leri anlamak
LLM‘ler devasa verilerle, NLP (Doğal dil işleme) yöntemleri sonucu oluşturulmuş modelleridir 3 .
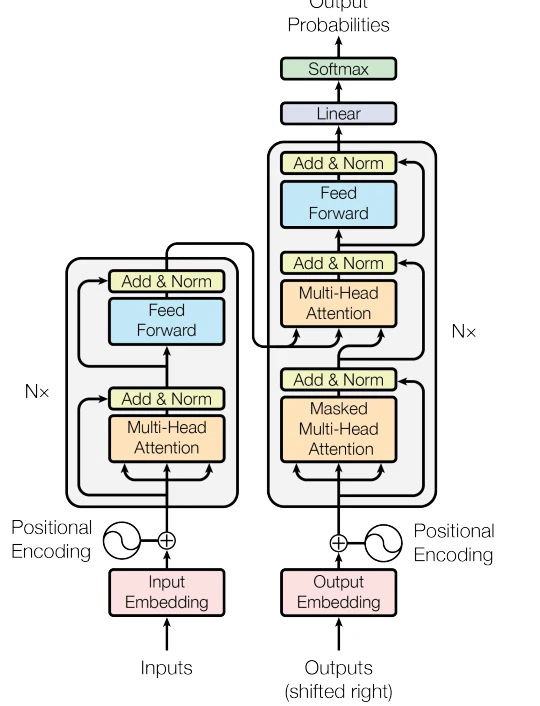
Dil modellerinin tarihi eskiye dayansa da, günümüzdeki Büyük Dil Modelleri için bir dönüm noktası 2017 yılında Google Brain (günümüzde Google DeepMind) ekibinin yayımladığı “Attention is All You Need” başlıklı makale olmuştur 4 . Bu makale, “Transformers” adı verilen ve “dikkat” (attention) mekanizmasını kullanan devrimci bir mimariyi tanıttı. Bu mimarinin temelinde, bir metni anlamak için “encoder” (kodlayıcı) ve yeni bir metin üretmek için “decoder” (kod çözücü) olmak üzere iki ana blok bulunur.
Bu güçlü mimari, zamanla iki farklı yaklaşımın doğmasına neden oldu:
-
Üretim Odaklı Modeller: GPT ve türevleri bu yaklaşıma en iyi örnektir. Adından da anlaşılacağı gibi (“Generative Pretrained Transformer”), bu modellerin temel amacı metin üretmektir. Bu nedenle Transformer yapısının yalnızca “decoder” (üretici) bloğunu kullanırlar 5 .
-
Anlama ve Üretme Odaklı Modeller: Google’ın “BERT” modeli gibi diğer yapılar ise metni derinlemesine anlamayı hedefler. Bu amaçla, mimarinin hem encoder hem de decoder bloklarını çift yönlü (bidirectional) bir şekilde kullanırlar. Bu yapı, onları çeviri araçları gibi hem anlamanın hem de üretmenin kritik olduğu görevler için ideal kılar 6 .
Modelin, kavramları bir vektör uzayında nasıl grupladığını anlattık: “kral” ve “prens” gibi kelimeler bir araya gelirken, “kraliçe” ve “prenses” başka bir yerde kümelenir. Bu durum akla şu mantıklı soruyu getiriyor: Eğer model matematiksel olarak en yakın vektörleri seçiyorsa, aynı soruya neden her zaman birebir aynı cevabı vermiyor?
Bu sorunun cevabı, modellerden beklentimizde gizli: yaratıcılık. Eğer bir model her defasında en olası, en “doğru” cevabı verseydi, deterministik ve sıkıcı olurdu. “Ama matematik deterministik değil mi?” diye düşünebilirsiniz. Evet, temelindeki matematik kurallara bağlıdır, ancak LLM‘ler basit birer hesap makinesi değildir. Onlar, bir sonraki kelimeyi olasılıklara göre tahmin eden dil üreticileridir. İşte bu noktada devreye, modelin davranışına bilinçli olarak eklenen küçük bir rastgelelik faktörü giriyor. Bu faktör sayesinde model, her zaman en bariz yolu seçmek yerine, farklı ve yaratıcı metinler üretebiliyor. Meraklısı için “Temperature” ve “Top_p” terimlerine bakabilirler 8.
Diyelim ki ChatGPT’ye “İstanbul’un yakaları nelerdir?” dediniz.
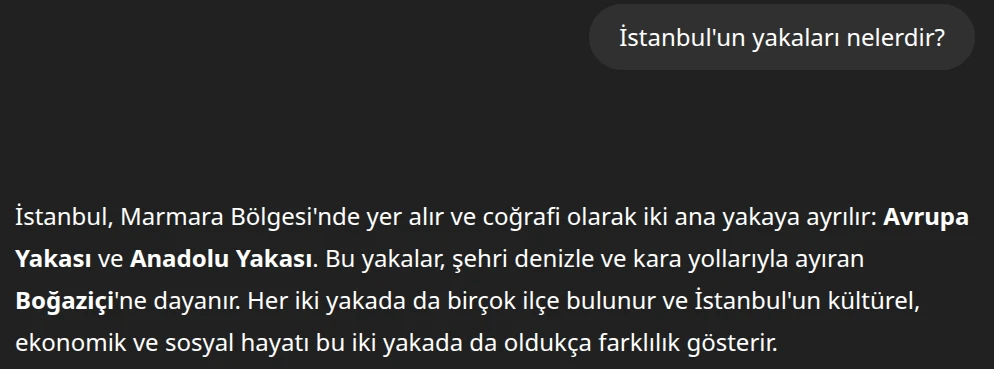
O da böyle bir yanıt verdi. Peki şimdi de “İstanbul’un yakalarından bir hikaye yazar mısın?” diyelim.

Yeni bir sohbette tekrar isteyelim:
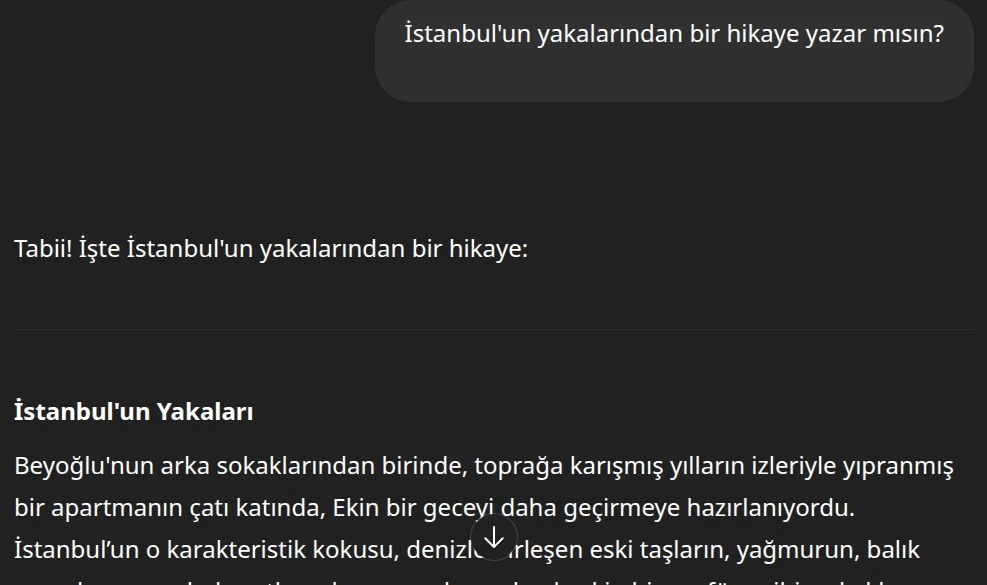
Beklediğimiz üzere farklı bir çıktı verdi.
Peki tekrar “İstanbul’un yakaları nelerdir?” dediğimizde de mi farklı bir yanıt verecek?
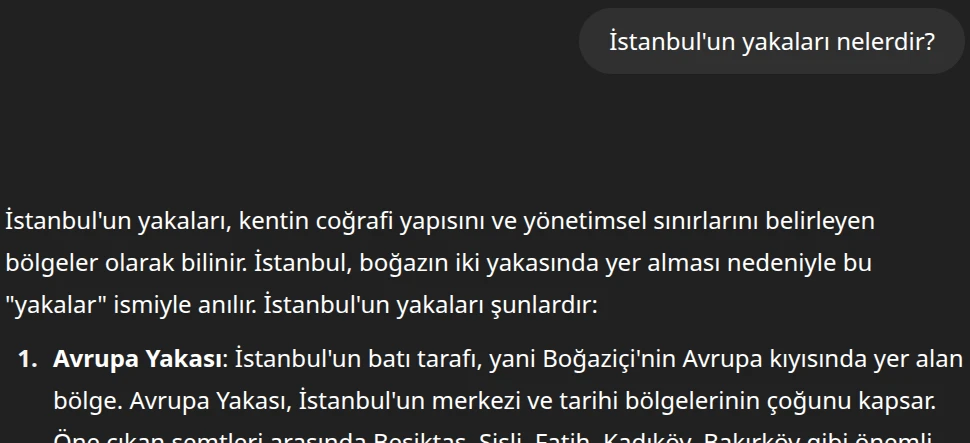
Tabii ki de hayır aynı çıktıyı verecek ve vermeli de çünkü İstanbul’un iki yakası sabittir!
Yani bizim rastgelelik dediğimiz şey, sorduğunuz sorunun tipine göre farklılık gösterir. Örneğin, ‘İstanbul’un yakaları nelerdir?’ gibi net bir soruda rastgelelik daha çok cevabın nasıl verildiğini (nitelik) etkilerken; ‘Bana bir hikaye anlat’ gibi yaratıcı bir istekte ise cevabın ne olduğunu (nicelik) tamamen değiştirir
Model, kelimeleri vektör uzayında temsil eder ve benzer anlamlara sahip kelimeleri bir araya getirir. Örneğin, erkek, kral, prens ve baba gibi kelimeler birbirine yakın olurken, kadın, kraliçe, prenses ve anne gibi kelimeler de kendi aralarında yakınlaşır. Bu sayede, cinsiyetler, aile üyeleri ve nitelikler gibi kategoriler arasındaki ilişkiler daha net bir şekilde modellenir. Sonuç olarak, derin öğrenme bu tür ilişkileri keşfederek veriler arasında anlamlı bağlantılar kurar.
Farkı gördünüz değil mi? Benim yarı bozuk lisanım ChatGPT ile statik ve katı bir yapıya büründü.
Peki neden her seferinde birebir çıktıyı vermez modeller? Şöyle açıklayayım:
1
Sizin prompt'ta yazıp yazmadığınız nokta bile çıktıyı değiştirirken 128 tane gizli katmanlı ve bir o kadar da karmaşık bir model mimarisinden her seferinde aynı çıktıyı beklemek? Ütopik açıkçası.
Bir de tabii biz kasti şekilde rastgelelik sağlamaya çalışıyoruz ancak oralara bu yazıda girmeyeceğim
Ancak şunu eklemeden edemeyeceğim: Model ne düşündüğünü, hatta çıktı verdiğini, hatta ve hatta çıktı verip vermediğini bile bilmiyor (Ta ki siz yeni prompt girene kadar)
Ancak araştırılan ve geliştirilen mekanizmalarla bu durum değişebilir (ChatGPT “o” serisi bunun için var 9)
Halüsinasyonları anlamak
Yazıya başlamadan önce hepinizden ChatGPT’de (ama o serisi değil sebebini anlatacağım) yeni bir sohbet açıp ona “Türkiye kelimesinde kaç tane ‘e’ harfi vardır?” demenizi istiyorum. Biz de deneyelim:
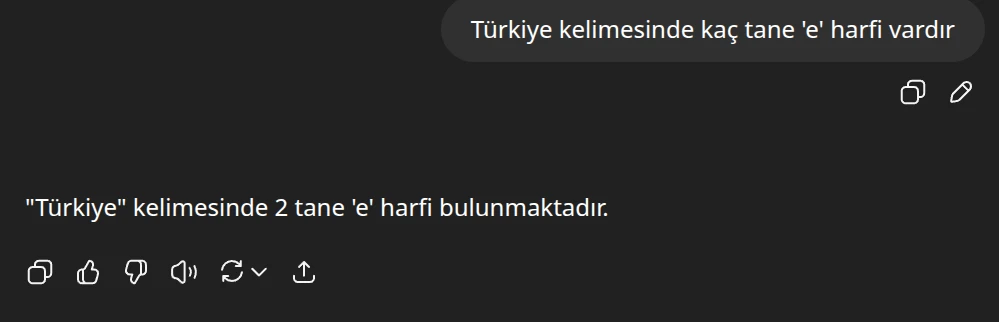
Gördüğünüz gibi… Şimdi düşünelim, nasıl olur da çalıştırılması için sunucu kümesi kullanılan ve eğitimi için internette girilmedik kaynak kalmayan bu model, nasıl olur da bunu yapamaz. Sebebi çok basit: O düşünmüyor ki! Az önce de anlattım;
1
...Model ne düşündüğünü, hatta çıktı verdiğini, hatta ve hatta çıktı verip vermediğini bile bilmiyor...
O sadece varsa internette gördüğü eski bilgisini sizlere açıklıyor. Peki ya görmediyse? Ya yanlışsa? Ya sadece türevini gördüyse ve genelleyemezse?
İşte buna halüsinasyon deniyor.
Tıpta halüsinasyon, bir kişinin gerçek olduğuna inandığı ancak gerçek olmayan görüntü, ses, koku gibi duyuları hissetmesidir ^1 .
LLM’ler ise özellikle geliştikçe kendilerine aşırı güvenerek alakasız, uydurma ve tutarsız içerik üretirler ^2 . Bu bilgiler tamamen yanlış veya uydurma olabileceği gibi kendini bir anda insan gibi görmeye ve yaşamadığı şeyleri yaşamış gibi anlatmasına da neden olabilir.
Ai dünyası için halüsinasyon
Elimden geldiğince basitleştirerek anlatmaya çalışacağım. Burada 24 Ocak 2025’de yayımlanan oldukça yoğun bir makaleden yaranlandım 7 .
LLM’lerin halüsinasyonlarını iki ana kategoriye ayırabiliriz: Gerçeklik Halüsinasyonları ve Sadakat Halüsinasyonları. Gerçeklik halüsinasyonları, modelin gerçekte doğru olan bilgiyi yanlış sunması, yani ‘gerçeklik çelişkisi’ yaşamasıyla ortaya çıkar. Örneğin, ‘Thomas Edison telefonun icadını yaptı’ gibi yanlış bir ifade kullanması buna örnektir. Ya da, gerçek bir bilgiye tamamen uydurma, dışarıdan doğrulanamayan eklemeler yapabilir, buna da ‘gerçeğe dayalı uydurma’ denir. Modelin belirli bir kişi hakkında uydurma atıflar söylemesi bu kategoriye girer.
İkinci ana kategori olan Sadakat Halüsinasyonları ise modelin verilen talimatlara veya bağlama sadık kalmamasından kaynaklanır. Buna ‘talimat tutarsızlığı’ denir; örneğin kullanıcı Türkçe bir şey sorduğunuzda modelin İngilizce yanıt vermesi gibi. ‘Bağlam tutarsızlığı’ ise bir özet istendiğinde metni hatalı özetlemesiyle kendini gösterir. Son olarak, modelin matematiksel işlemlerde veya mantıksal çıkarımlarda hata yapması da ‘mantık uyuşmazlığı’ olarak adlandırılır.
Aşağıda bu konuda bir tablo bulabilirsiniz:
| Ana Tür | Alt Tür | Örnek |
|---|---|---|
| Gerçeklik Halüsinasyonu | Gerçeklik Çelişkisi | “Thomas Edison telefonun icadını yaptı.” gibi yanlış bir ifade. |
| Gerçeğe Dayalı Uydurma | Modelin bir kişi hakkında uydurma atıflar söylemesi. | |
| Sadakat Halüsinasyonu | Talimat Tutarsızlığı | Kullanıcı Türkçe bir şey sunduğunda modelin İngilizce yanıtlaması. |
| Bağlam Tutarsızlığı | Bir özet istendiğinde modelin metni hatalı özetlemesi. | |
| Mantık Uyuşmazlığı | Matematikte yaptığı işlem hataları veya hatalı çıkarımlar. |
LLM’ler Neden Bazen “Uydurur”?
Büyük Dil Modelleri’nin (LLM’ler) zaman zaman “uydurma” olarak tabir ettiğimiz, yani yanlış veya tutarsız bilgiler üretme eğilimi, genellikle üç ana kategoride incelenebilir: eğitim verilerinden kaynaklanan sorunlar, eğitimin kendisindeki zorluklar ve çıktı üretme sürecindeki hatalar.
İlk olarak, eğitim verilerinden kaynaklanan sorunlar halüsinasyonların temelini oluşturabilir. Eğer modelin üzerinde eğitildiği devasa veri setleri yanlış veya eksik bilgiler içeriyorsa, model bu boşlukları kendi kendine “doldurmaya” çalışır ve bu da uydurma bilgilere yol açar. Aynı zamanda, eğitim verilerindeki belirli önyargılar veya kalıplar, modelin gerçekleri çarpıtmasına neden olabilir. Ayrıca, modelin belirli bir görevi veya kullanıcı isteğini tam olarak anlayıp uygulayamaması da, yetersiz yönlendirme nedeniyle yanlış yanıtlar vermesine sebep olabilir.
İkinci kategori olan eğitimin kendisindeki zorluklar da halüsinasyonlara zemin hazırlar. Modelin ilk ve genel eğitiminde oluşan bazı “kötü alışkanlıklar”, daha sonraki ince ayar aşamalarında da devam edebilir. Modeller, insan geri bildirimleriyle sürekli olarak daha iyi hale getirilir; ancak bu geri bildirimler yetersiz veya yanlış yönlendirilirse, model hala uydurma bilgileri doğru sanabilir.
Son olarak, çıktı üretme sürecindeki hatalar da halüsinasyonlara yol açabilir. Modelin en iyi cevabı seçme veya kelimeleri bir araya getirme şeklindeki kusurlar, bazen mantıksız veya yanlış çıktılar doğurabilir. En ilginç durumlardan biri ise modelin aslında emin olmadığı bir konuda bile, çok kendinden emin bir şekilde yanlış bir yanıt vermesi, yani “fazla öz güven” sergilemesidir. Özellikle karmaşık sorulara adım adım cevap vermesi gereken durumlarda, modelin mantık yürütme zincirinde kopukluklar olması da düşünme hatalarına yol açar (eğer düşünme zincirine sahip bir modelse).
| Ana Kategori | Neden |
|---|---|
| 1. Eğitim Verilerinden Kaynaklanan Sorunlar | Yanlış veya Eksik Bilgiler |
| Yanlı Bakış Açıları | |
| Yetersiz Yönlendirme | |
| 2. Eğitimin Kendisindeki Zorluklar | Temel Eğitimden Gelen Sorunlar |
| İnsan Geri Bildirimlerinin Eksikliği veya Yanlış Yönlendirmesi | |
| 3. Çıktı Üretme Sürecindeki Hatalar | Cevap Üretme Yöntemlerindeki Kusurlar |
| Fazla Özgüven | |
| Düşünme Hataları | |
Halüsinasyonları Nasıl Azaltırız? (Veya azaltabilir miyiz?)
Bu sorunu çözmek için çeşitli yaklaşımlar bulunmakta olup, bunları üç ana kategoriye ayırabiliriz: daha iyi veri kullanmak, eğitimi geliştirmek ve çıktı üretme mekanizmalarını iyileştirmek.
İlk olarak, daha iyi veri kullanmak halüsinasyon riskini önemli ölçüde azaltabilir. Modelleri eğitmek için mümkün olduğunca doğru, güncel ve yanlılıktan arındırılmış veri kümeleri kullanmak esastır. Ayrıca, modelin bilmediği konularda “emin değilim” diyebilmesini veya yalnızca bildiği konularda konuşmasını sağlamak, yani bilgi sınırlarını belirlemek kritik öneme sahiptir. Kullanıcıların ne istediğini daha iyi anlaması ve buna göre doğru cevaplar üretmesi için modele daha net ve kaliteli “eğitim örnekleri” sağlanması da halüsinasyonları engellemeye yardımcı olur.
İkinci olarak, eğitimi geliştirmek de çözümün önemli bir parçasıdır. Modelin temel eğitim ve ince ayar (özel görevler için eğitilme) aşamalarını, halüsinasyon riskini en aza indirecek şekilde tasarlamak gerekir. Bununla birlikte, modelin yanlış veya uydurma yanıtlar verdiğinde bunu anlayacak ve kendini düzeltecek daha akıllı geri bildirim mekanizmaları kullanmak, modelin zamanla daha güvenilir olmasını sağlar.
Son olarak, çıktı üretme mekanizmalarını iyileştirmek de halüsinasyonlarla mücadelede etkilidir. Modelin bir soruya cevap verirken en doğru ve mantıklı seçeneği belirlemesini sağlayacak gelişmiş teknikler kullanmak (örneğin, belirli bir “sıcaklık” ayarıyla daha tahmin edilebilir cevaplar üretmek) daha akıllı cevap seçme yöntemlerini içerir. Bu noktada öne çıkan bir yöntem, Harici Bilgilerle Destekleme (RAG - Retrieval Augmented Generation) yaklaşımıdır. Bu yöntemde model, sadece öğrendiklerine dayanmak yerine, bir nevi “kütüphaneye danışarak” cevap verir. Güvenilir kaynaklardan bilgi çekerek uydurma olasılığını büyük ölçüde azaltır. Ayrıca, modelin ürettiği yanıtların doğru ve kendi içinde tutarlı olup olmadığını kontrol eden ek mekanizmalar eklemek ve karmaşık problemleri çözerken insan gibi adım adım düşünmesini ve plan yapmasını sağlayan teknikler kullanmak (Chain-of-Thought prompting gibi) daha iyi düşünme becerileri geliştirmesine yardımcı olur.
| Ana Kategori | Çözüm |
|---|---|
| 1. Daha İyi Veriler Kullanmak | Doğru ve Temiz Veri |
| Bilgi Sınırlarını Belirleme | |
| Daha İyi Yönlendirme Verileri | |
| 2. Eğitimi Geliştirmek | Eğitim Süreçlerini Optimize Etmek |
| Akıllı Geri Bildirim Sistemleri | |
| 3. Çıktı Üretme Mekanizmalarını İyileştirmek | Daha Akıllı Cevap Seçme Yöntemleri |
| Harici Bilgilerle Destekleme (RAG) | |
| Cevapları Kontrol Etme | |
| Daha İyi Düşünme Becerileri |
“Bu büyük dil modelleri, bizlere hem bilginin sonsuzluğunu hem de yanılgının kaçınılmazlığını gösteriyor. Onlarla kurduğumuz diyalog, aslında kendi “doğruluk” arayışımızın bir yansımasıdır; geleceğin dijital dünyasında bilgelik, bu sorgulamadan doğacaktır.”
Kaynakça
- Memorial Sağlık Grubu - Halüsinasyon ve Varsanı Nedir?
- Lakera.ai - The Beginner’s Guide to Hallucinations in Large Language Models
- Google Cloud - Large Language Models powered by world-class Google AI
- Vaswani, A., et al. (2017). Attention is all you need. NeurIPS
- OpenAI — Understand Foundational Concepts of ChatGPT and cool stuff you can explore!
- Devlin, J., et al. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- Huang et al., 2024. A Survey on Hallucination in Large Language Models
- Understanding OpenAI’s “Temperature” and “Top_p” Parameters in Language Models
- Wei et al., 2023. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
- The Delegated Chain of Thought Architecture