Dil Modellerinde Düşünme Zincirlerinin Kırılganlığı Üzerine
CoT’nin (düşünme zinciri) güvenlik ve açıklanabilirlikteki rolü, latent reasoning’in yükselişi ve süreç gözetimi/gerekçe damıtımı gibi tekniklerle şeffaflığın neden kırılganlaşabileceği.

İnsan dilinde “düşünen” yapay zeka sistemleri, yapay zeka güvenliği için benzersiz bir fırsat sunar: bu sistemlerin düşünce zincirlerini (CoT) izleyerek kötü niyetli davranışları tespit edebiliriz. Diğer tüm bilinen yapay zeka denetim yöntemleri gibi, CoT izleme de kusursuz değildir ve bazı kötü niyetli davranışların fark edilmeden kalmasına izin verir. ~ Chain of Thought Monitorability, arXiv:2507.11473
Temmuz ayında OpenAI , Google DeepMind , Anthropic ve Meta’dan bilim insanları, yapay zeka güvenliği konusunda ortak bir uyarı yayınladılar . Bu rakip şirketlerdeki 40’tan fazla araştırmacı, bugün yapay zekanın akıl yürütmesini izlemek için kullandığımız düşünme zinciri diye çevirebileceğimiz CoT mimarisinin yakında şu anki kadar şeffaf olamayabileceğinden bahsettiler. Biz de bu durumu dilimiz döndüğünce ele almaya çalışacağız.
Düşünce zincirinin sadakati ve yorumlanabilirliğinin potansiyeli beni son derece heyecanlandırıyor. Bu potansiyel, o1-preview ile başlayarak, akıl yürütme modellerimizin tasarımını önemli ölçüde etkiledi. ~ Jakub Pachocki — OpenAI
1. İnsan-yapay zeka etkileşiminde güven ve açıklanabilir Yapay Zeka
1.1 İnsan makine etkileşiminde güven
Cornelia Becker ve Mahsa Fischer‘ın çalışmalarına göre büyük dil modelleri, insan benzeri yanıtlar üretme ve doğal sohbetler yürütme kapasiteleriyle dikkat çekmekte ve güven insan-makine etkileşiminde güvenin temel bir unsur olduğu vurgulanmaktadır. Uzun süreli etkileşimlerde, LLM’lerin giderek kişiselleşmesi ve “insanlaşması” kullanıcıların daha fazla güven duymasına yol açabilir. Bazı kullanıcılar, yapay zeka ile sohbet ettikçe bir “kimlik” ile konuştuklarını hissettiklerini belirtmiştir 4. Ayrıca ilk promptun, LLM’nin bir kişilik veya rol üstlenmesini sağlayarak, yanıtların stilini, tonunu ve odak noktasını belirlemeye yardımcı olduğu da bilinmekte9.
Sohbet yapay zekalarında güven oluşturan faktörler 3:
- Kontrol Edilebilirlik
- Uyarlanabilirlik
- Şeffaflık
- Samimiyet
- Empati
- Etkileşim
- Antropomorfizm (Sistemin insan benzeri özellikler sergilemesi)
- Güvenlik
1.2 Açıklanabilir Yapay Zeka (XAI)
Son kullanıcının modelin cevap olarak sunduğu argümanın arka planındaki nedeni bilmemeleri güven kırmakta ve ön yargılara neden olmakta. Buna jargonda kara kutu problemi denmekte ve XAI, bu kara kutu problemini ele almakta.
XAI neden önemli:
- Güven Ortamı Oluşturma
- Hesap Verebilirlik ve Sorumluluk Sağlama
- Hata Ayıklama ve İyileştirmeyi Kolaylaştırma
- İnsan-Yapay Zeka İş Birliğinin Geliştirilmesi
XAI Nasıl geliştirilir:
- Dikkat Mekanizmaları: Modelin girdi metninin hangi kısımlarına odaklandığını görselleştirir.
- Saliency Haritaları/Özellik Atfı: Hangi kelime veya ifadelerin modelin kararı üzerinde en çok etkisi olduğunu vurgular.
- Karşı Olgusal Açıklamalar: Girdideki küçük değişikliklerin modelin çıktısını nasıl etkileyeceğini gösterir.
- Katman Bazında Alaka Yayılımı (LRP): Sinir ağı tahminlerini katman katman parçalayarak bilgi akışını izler.6
2. Chain of Thought-Modelin aklından geçenler
Aslında düşünme zinciri bir prompt mühendisliği ürünüdür.
- Ne katman sayısı arttı
- Ne özel CoT bloğu eklendi
- Ne de özel token eklendi
Tek fark: Prompt’ta ek bilgi verildi.
Yani modele şöyle dendi:
“Aşağıdaki matematik sorusunu adım adım düşünerek çöz.”
Antrparantez: mevcut teorik ve bazı yeni teknikleri saymazsak (bkz. process supervision (süreç gözetimi/denetimi) / rationale distillation (gerekçe/akıl yürütme damıtımı)). Ancak temelinde CoT bir prompt mühendisliğidir. Az önce belirttiğim teknikler ise CoT olarak planlanan modellerin eğitim teknikleridir.
İşte bu yüzden CoT, hem açıklanabilir yapay zeka hem de güvenlik açısından eşsiz bir fırsat sunuyor. Çünkü mimari olarak değişen bir şey yok. Bu modeller sanki bir çocuğa matematik öğretirken işlemleri göstermesini isteyip doğru çözdüğünde ödül, yanlış çözdüğünde ise ceza vermek gibi.
-
Örneğin:
-
Ali 5 elma aldı, 3’ünü yedi, sonra 2 elma daha aldı. Kaç elması var?
-
Model eğer “Hemen 4” diyorsa hata yapıyor.
-
Ama önce şöyle düşünürse:
Ali’nin 5 elması vardı → 3’ünü yedi → 2 kaldı → 2 elma daha aldı → toplam 4
-> o zaman doğru yanıt geliyor.
-
Düşünme zinciri ile eğitilen modeller (yani en başından modele böyle bir promptun varlığını göstererek eğitilenler), kodlama, analitik yetenekler, matematik gibi alanlarda diğer modellere kıyasla oldukça yüksek başarı sağlamakta.
Peki şu “1 dakika boyunca düşündü” çıktısı? Bu gecikme aslında token üretiminden kaynaklanıyor; model yazıyor ama biz ilk token gelene kadar hiçbir şey görmüyoruz. İlk token üretilmeden önce biz bir şey görmeyiz ama model aslında arkada cevabı hazırlıyor. Hatta bazen bir anda önünüze 1 sayfa cevap fırlatabiliyor sistem. Düşünme sırasında ise bizlere aklından geçenleri yazıyor. Peki ya tüm bunlar bir blöf ise? Buna 5. bölümde değineceğiz öncesinde biraz daha ön bilgi verelim.
3. Güvenlik açısından değeri nedir? Kötü niyeti nasıl yakalayabiliyoruz?
CoT’un güvenlik açısından avantajı, akıl yürütmeyi görünür kılmasıdır. Yani;
-
Mantıkta bir hata varsa bunu erkenden fark edebiliriz.
-
Adım-çıktı tutarsızlığı yakalanır: “A,B,C” deyip X çıkarıyorsa, yalan olabilir. Yine de unutmamak gerekir ki CoT izleme güvenliğe katkıda bulunsa da kusursuz değildir. Bazı kötü niyetli davranışlar görünmeyebilir.
3.1 Kötü niyeti nasıl yakalarız?
-
Amaç-araç uyumu testi: Hedef ile yapılan işlemin eşleşip eşlemediği incelenir
-
Adım-çıktı tutarlılığı: Gidilen adımlar ile çıkan sonuçta verilen çıktı farklıysa mantık hatası veya aldatıcı açıklama olabilir.
-
Çapraz Sorgu ve varyant üretimi: Aynı soru farklı prompt stillerinde çelişiyorsa hikaye yazmış olabilir ya da saklıyor olabilir. XAI yazınında anlatı açıklamaları doğruluk/sadakat açısından ölçülmelidir.
4- CoT’un geleceği neden kırılgan? Ne bozar, ne yok eder?
CoT’un geleceği hakkında en önemli gelişmelerden biri OpenAI, DeepMind, Anthropic ve Meta’dan kırk kişiden fazla araştırmacının uyarısıdır: “Bugün CoT şeffaflığı geçici olabilir, gelecekteki modeller iç seslerini gizleyebilir2”. Yani CoT’nin şeffaflığını kaybetme olasılığından bahsediliyor burada. Şimdi biraz daha detaylı şekilde bunun nedenlerine bakalım:
-
Latent Reasoning- İçten içe düşünme, dışa vurmama: Bugün CoT şeffaf şekilde kullanılıyor, model adım adım metin üretiyor ve bunlar okunabilir biçimde oluyor. Ancak yeni trend akıl yürütmenin dil üzerinden değil, gizli temsiller üzerinden yapılmasında8. Model düşünmeye ve akıl yürütmeye devam ediyor, ancak bunu “iç sesi” ile yapıyor ve yazıya dökmüyor. Bu durum performans için olumlu olsa da güvenlik açısından oldukça kötü bir gelişme.
-
Sahte düşünme zinciri riski: CoT modeller her zaman dürüst bir şekilde yaptığını açıklamıyor. Model sonucu bulduğu anlatmak yerine kullanıcıya bir “hikâye” yazarak arkadan yaptığı farklı tür işlemleri gizliyor.6
Bu durum CoT için güvenilirliği zedeliyor.
-
Ekonomik ve teknik zorluklar: IBM’in analizine göre uzun CoT, daha fazla hesaplama istediği için maliyeti de daha yüksek oluyor1. Şirketler bu maliyetten kaçınmak için kısa ve hızlı akıl yürütmeye kayıyor ancak bunu yaparken şeffaflıktan ödün veriyorlar.
-
Kötü niyetli bypass: Kullanıcı veya modelin CoT’u atlatma ihtimali vardır. “Düşünce ve adımları saklayıp sadece cevabı ver” benzeri promptlarla sistemleri manipüle etmek mümkündür. 7 Bu durumlarda CoT güvenlik için devre dışı kalmış olur, bu da geleceğinin kırılgan olmasında önemli bir etken oluşturur.
5. Bilerek iç seslerini gizlemeleri mümkün mü veya gizlemeden bizlere “-mış” gibi yapabilirler mi?
Bir önceki başlıkta aslında bu sorulara cevap vermiş olduk. Modellerin;
Modelden adım adım düşün talebi gelmezse veya model bilinçli şekilde CoT’yi bastıracak şekilde eğitilebilir1. Latent Reasoning yöntemiyle akıl yürütme dil ile değil gizli temsillerle gösterilerek içeride kalır8
Model sahte bir adım zinciri oluşturabiliyor. 6 (XAI literatüründe plausible but unfaithful explanations (inandırıcı fakat (modelin) gerçek gerekçesine sadık olmayan açıklamalar) denir 7. IBM’de CoT’un açıklamaları “ikna edici görünür ancak sahte olabilir” şeklinde bu yöne dikkat çekiyor1.
Yani evet, iç seslerini gizleyebilirler veya gizlemeden bizlere “-mış” gibi yapabilirler. Bu nedenle CoT’a olan güveni “kırılgan” olarak niteleyebiliriz.
6. CoT’un yeterlilikleri, yetersizlikleri ve alternatifleri7
Düşünce Zinciri’nin keşfi halihazırda insan diliyle konuşan yapay zekanın daha da açıklanabilir olması umudu güçlendirdi. Modellerin yüksek sesle düşünmesini sağlamak, yeteneklerini geliştirirken aynı zamanda doğal dilde gerçekleşen ilgili hesaplamaların oranını da artırır. Ancak yukarıda da saydığımız hususlardan kaynaklı CoT modellerinin de yetersizlikleri oldukça fazladır. Aşağıda bu zinciri kıran bazı sorunlar bulunmaktadır:
- Pekiştirmeli öğrenme (reinforcement learning) kullanıldığında model düşünme zincirinin doğru-yanlış olmasına göre puan almakta. Ancak zincirin açıklanabilir olmasına göre puan almamakta. Bu da modelin doğruyu açıklamadan bulmasına teşvik etmektedir.
- “Süreç denetimi” (process supervision) adı verilen yöntemlerle, modelin nasıl düşündüğü de doğrudan kontrol edilmeye çalışılıyor. Örneğin:
- Düşünce zinciri daha kısa olsun,
- Geçerli adımlarla düşünsün,
- Belirli bir stil kullansın,
- Uygunsuz ifadeler içermesin.
Bu tür denetimler, CoT’ların modelin gerçek düşünce sürecini yansıtmasını bozabilir. Öte yandan bunlar yaşanmayıp fayda da sağlayabilir. Daha fazla araştırmaya ihtiyacımız var.
- CoT doğrudan ödüllendirilmemiş olsa bile, eğitim süreci dolaylı olarak zinciri de etkileyebilir. Örneğin çıktılar bir tercih modeline (preference model, bu insanların feedbacki de olabilir) göre optimize edilirse bu model üzerinde baskı yaratır. Bu sorun çok basit bir şekilde de olabilir. Örneğin model hile yapmaya çalışırken hile önlense de bu model üzerinde baskı yaratır.
Yeni mimari yaklaşımları
Şu anki büyük dil modelleri, çok adımlı karmaşık düşünmeleri ancak CoT kullanarak yapabiliyor. 7 Ancak araştırmacılar, modellerin iç düşüncelerini dil yerine sürekli matematiksel temsillerle (latent space, temsil/gizli uzay) ifade ettiği yeni mimari yaklaşımlar üzerinde çalışıyorlar. Bu latent reasoning modelleri, düşüncelerini hiç kelimelere dökmeden muhakeme yapabilir. Bu durumda da CoT’un sağladığı şeffaflık ve güvenlik avantajları tamamen ortadan kalkabilir.
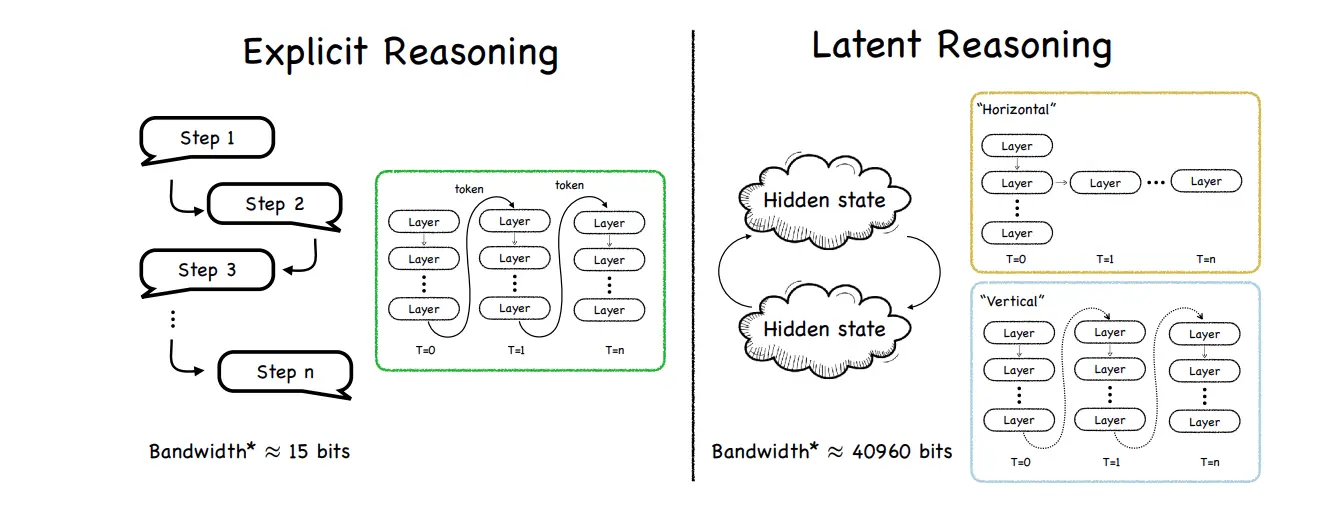
Explicit Reasoning, bugün GPT’lerde gördüğümüz klasik Chain of Thought yaklaşımı iken, Latent Reasoning ise modelin aklından geçenler kelimeye dökülmeden, kendi içinde gizli (latent) temsil olarak kalıyor. Nasıl çok çalıştığımız bir gün sonunda gece yatmadan önce aklımızdan aşırı hızlı bir şekilde anlamsız düşünceler geçiyorsa, latent reasoning de modelin aklından çok hızlı şekilde -ama bu sefer anlamlı (?)- düşünceler geçiyor. Öyle ki bu içsel bilgi taşıma kapasitesi (bant genişliği) makaleye göre 40960 bit’e kadar çıkmakta. Ama bu durumda açıklanabilirlikten ödün verip, verimliliğe pay veriyoruz. 8
7. Kapanış
“Düşünme zincirleri, bize yapay zekanın şeffaflık vaadini fısıldarken aynı anda onun kırılganlığını da açığa vuruyor. İç seslerini duyduğumuz sürece kontrol bizdeymiş gibi hissediyoruz; ama sustuklarında kimin gerçekten düşündüğünü bilemeyeceğiz. Geleceğin güvenliği belki de tam bu ince çizgide şekillenecek: neyi görmek istediğimizle, neleri asla göremeyeceğimiz arasında.”
Kaynakça
- What is chain of thought (CoT) prompting?
- OpenAI, Google DeepMind and Anthropic sound alarm: ‘We may be losing the ability to understand AI’
- Factors of Trust Building in Conversational AI Systems: A Literature Review
- Can LLMs and humans be friends? Uncovering factors affecting human-AI intimacy formation
- LLMs in Explainable AI: Refining Explanations and Evaluating Narratives
- XAI Meets LLM: Bridging the Gap Between Transparency and Intelligence
- Chain of Thought Monitorability: A New and Fragile Opportunity for AI Safety
- A Survey on Latent Reasoning
- Role Prompting - Learn Prompting